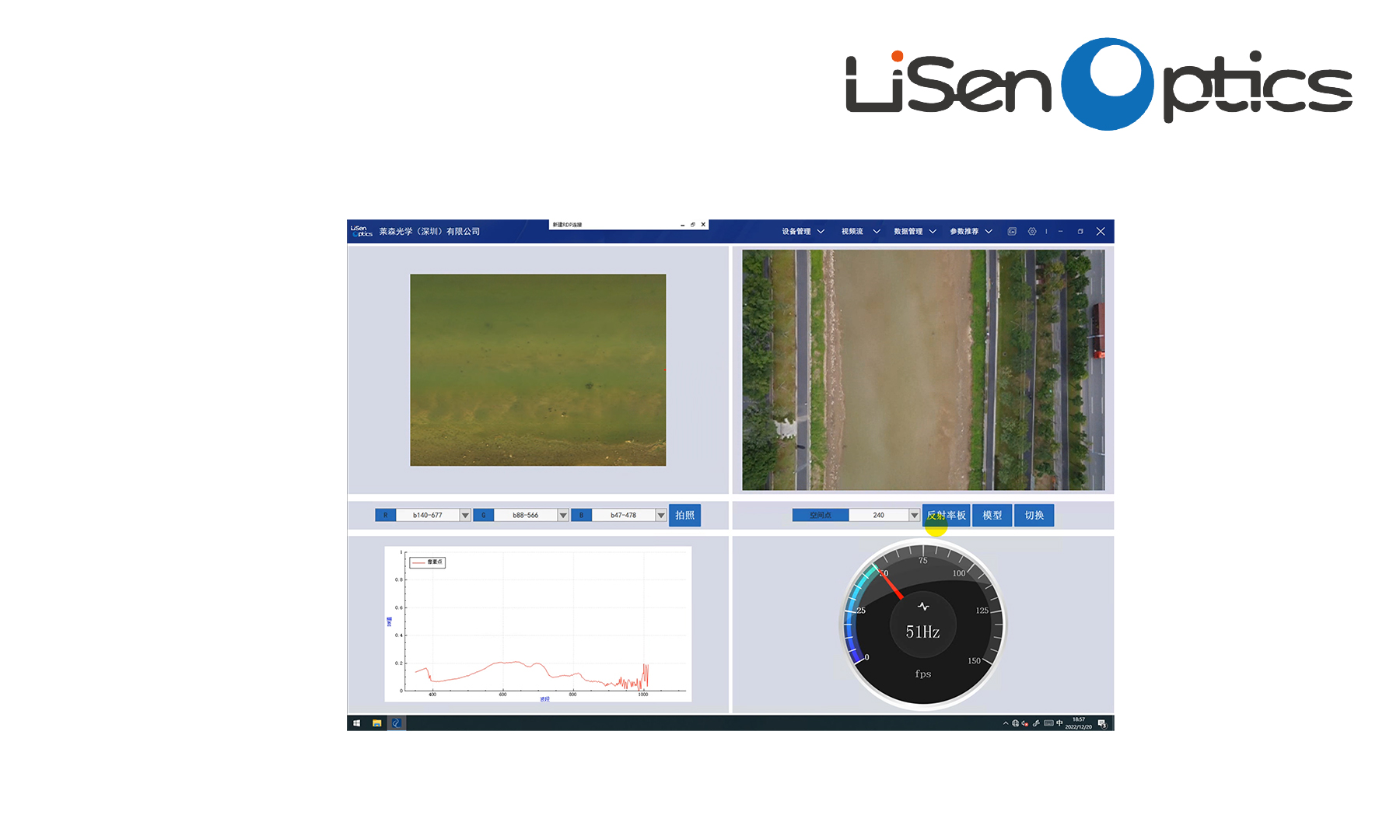
中文
中文
 English
English

专注光谱传感和光电应用系统
电话:86-0755-23229824
手机:18948346937 / 13510373651
邮箱:sales@lisenoptics.com
地址:深圳市光明区华强生态科技园四期8栋B座2单元805室
微信:
微信客服号:
抖音官方号:
在矿物分析领域,高维数据处理是一个十分关键的环节。高光谱矿物识别技术的出现,使得我们可以通过光谱信息来获取矿物的化学成分和结构特征,从而实现对矿区地质环境和矿床赋存规律的理解。然而,高光谱数据的维度往往非常高,导致数据处理和分析变得困难,需要采用合适的方法来处理和降维。本文将为您介绍深圳高光谱矿物识别厂家在处理高维数据时所采用的方法和技术。
特征选择是处理高维数据的首要任务,它的目标是从原始数据中选择出最相关的特征子集,以减少维度并保留最重要的信息。特征选择可以通过以下几种方法进行:
在特征选择之后,还需要进一步降低维度,以更好地处理高维数据。降维技术可以将原始数据映射到低维空间,同时尽量保留原始数据的结构和信息。

在处理完降维后的数据之后,就可以使用分类和识别算法来对矿物进行准确的识别和分类。常用的算法有:
在深圳高光谱矿物识别厂家的实践中,处理高维数据的方法主要包括特征选择、降维技术以及分类和识别算法的应用。通过合理的数据处理方法,可以提高高光谱矿物识别的准确性和效率,为矿物分析和勘探工作提供强有力的支持。