中文
中文
 English
English

专注光谱传感和光电应用系统
电话:86-0755-23229824
手机:18948346937 / 13510373651
邮箱:sales@lisenoptics.com
地址:深圳市光明区华强生态科技园四期8栋B座2单元805室
微信:
微信客服号:
抖音官方号:
基于可见/近红外反射光谱的稻米品种与真伪鉴别

引 言
近年来国内大米市场混乱,各种低档、劣质稻米冒充品牌稻米销售,严重侵犯了消费者的利益,甚至危及生命安全。而目前,稻米品质与品种的鉴别方法主要为感觉法与化学分析法。感觉法通过形状、色泽以及气味对大米品质进行鉴定,主要依赖鉴别者的经验,缺乏严格的科学依据;常规化学分析法则存在耗时长、耗资大以及操作复杂等缺点而难以满足市场经营中快速鉴别的需要.而可见/近红外反射光谱技术因其快速、高效以及无损的特点,已被广泛地应用于石油化工、探矿、制药以及纺织等领域。近年来,可见/近红外光谱结合模式识别技术,进一步在杨梅、燕麦等农产品的分类中获得了成功的应用,对丹参、白术、蛇床子等中药材产地与真伪鉴别也取得了满意的结果。在稻谷的相关研究中,可见/近红外光谱技术也已用于其直链淀粉、蛋白质、脂肪以及氨基酸含量与稻谷储存年份的分析。本文将采用可见/近红外反射光谱技术对稻米的品种与真伪进行鉴别,为稻米品种的快速无损鉴别提供新的方法。
1 材料与方法
1.1样本来源与数据采集
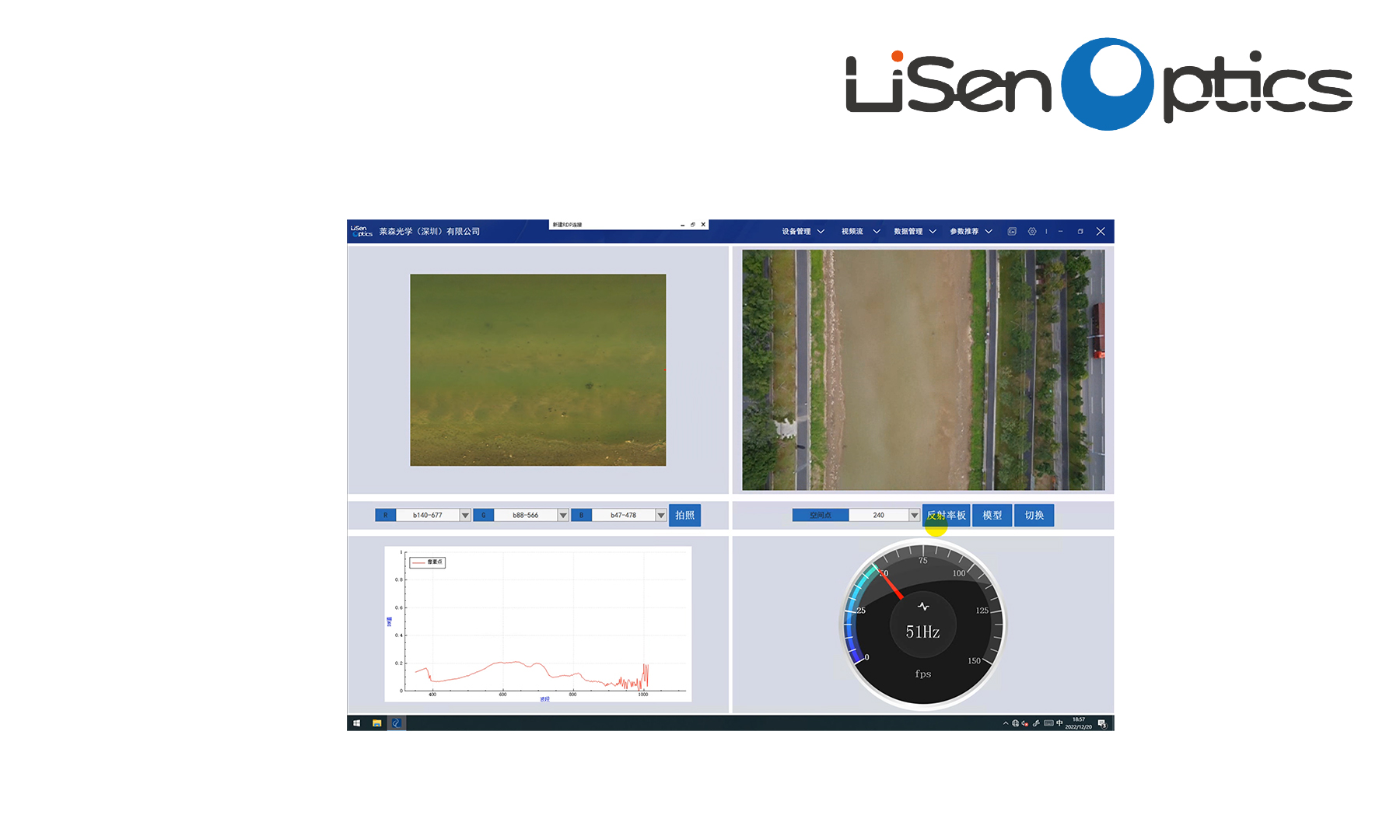
于超市购买了泰国香米、夜郎贡米、珍珠米、泰国糯米四种稻米样本;于湘西质量技术监督局获得劣质米(珍珠米伪品)样本。每种稻米采集样本35份,合计175份。随机抽取150份(每种30份)作为训练集,其余25份(每种5份)作为预测集。样本于45℃下恒温烘干24h后,于玻璃皿中进行光谱扫描,米样上表面均与玻璃皿上端保持平齐。测样于暗室中进行,以卤素灯为唯一光源.光纤探测器头部与样本之间保持垂直,下部距离样本0.5cm,每一样本重复测量30次取其均值。
1.2 光谱预处理
由于光谱在小于400nm与大于2300nm的波段噪声较大,因此本研究选用400~ 2300nm波段作为有效光谱数据进行分析。将有效光谱经S.Golay平滑后,采用标准归一化(SNV)方法进行除噪。
1.3 数据降维与波段选择
如果将光谱数据直接作为变量输入进行建模,不但会因变量太多而增加建模难度,而且会引入噪声而降低模型的预测精度。为了避免这一问题,本研究采用主成分分析(PCA)以实现光谱数据的降维。同时,如能选用特征波段进行建模,将信噪比低的波段删除,可能会获得比全波段建模更好的结果。因此,本研究将对全波段与特征波段两种建模方法进行比较分析以获得较优模型。
1.4 人工神经网络模型
在光谱分析中,人工神经网络是一种重要的模式识别方法,其中多层误差反向传播神经网络方法(back-propagation,BP)应用尤广,具有强大的非线性建模能力,特别适合解决复杂的映射问题。而作为一种有机物,稻米内部的理化性质与其可见/近红外反射光谱之间正是一种复杂的映射关系,因此,本研究将全波段与特征波段降维后的数据分别导入DPS中,采用BP算法建立不同稻米的鉴别模型。
2 结果与讨论
2.1 稻米样本的可见/近红外漫反射光谱
图1为5种稻米部分可见/近红外漫反射光谱曲线。从图中可看出,不同品种稻米的反射光谱的波形有稍许差异,而同种稻米样本的光谱则有一定的聚集趋势,但凭肉眼难以准确区分。分析时,先将光谱数据转化为ASCII码,在Unscramble 9.7中完成预处理后进行PCA分析。

图1 5种稻米样本的可见/近红外反射光谱
2.2 PCA分析与特征波段提取
训练集样本经PCA降维分析后,分别以前3个主成分PC 1、PC 2、PC 3作为x、y、z坐标,建立各样本的三维得分图(图2),以表征样本在该三维空间中的分布。由于前3个主成分对光谱矩阵的累积方差贡献达91.82%,因此,样本在三维空间的分布可大体反映其在超维空间的分布特征,表征出不同稻米的聚类结果。从图2中可看出,各种稻米有良好的聚类趋势,可进行定性分析,但要取得精确的定量分析结果,还需要建立鉴别能力更强的模型。
由于PCA分析的前3个主成分已包含了绝大部分的分类信息,因此,可根据不同波段的光谱对前3个主成分的贡献值分析出稻米分类的特征波段。在Unscramble 9.7中,得出前3个主成分的X-加载图,以表征各波段对模型前3个主成分的贡献大小(图3).以波谱区域对PC 1的贡献值为主要参考指标,并综合考虑对PC 2与PC 3的贡献值,得出400~500nm、910~1300nm与1940~2300nm三个波段为稻米鉴别的特征波段。根据水、淀粉、蛋白质的吸收特征,可分析出910~1400nm、1940~2300nm两段特征波段主要反映了不同稻米营养成分的差异,而400~500nm这一位于可见光部分的特征波段则主要反映了形状与颜色的差异。

图2 5种稻米前3个主成分的得分聚类

图3 不同谱区对PCA分析前3个主成分的贡献值

图4 两种模型训练集前12个主成分的累积可信度
在建立模型过程中,如果所选取的主成分过少,将会因不充分拟合而导致模型预测准确度降低;而若选用的主成分过多,则会产生过拟合现象而导致模型预测的准确率下降。因此,本研究通过交互验证确定最佳主成分数,即在累积可信度(累积方差贡献)变化不大的情况下选取较少的主成分数.将全光谱与特征光谱分别进行PCA分析后,所得前12个主成分的累积可信度如图4所示。由图可知,两种方法前9个主成分的累积可信度在99.5%以上,包含了光谱数据绝大部分的特征信息。
2.3 BP神经网络模型预测结果与比较分析
表1 两种模型对25个未知样本的预测结果

注:(1)~(5),泰国香米;(6)~(10),夜郎贡米;(11)~(15),珍珠米;(16)~(20),泰国糯米;(21)~(25),珍珠米伪品
利用训练集中的150个样本,以PCA降维得到的前9个主成分作为BP神经网络的输入变量,在DPS中建立PCA-BP神经网络预测模型。建模分析时,泰国香米、夜郎贡米、珍珠米、泰国糯米、劣质米分别赋值为1.0000、2.0000、3.0000、4.0000、5.0000;BP网络各层间采用Sigmoid激励函数,其中Sigmoid参数取0.9,动态参数取0.6,最小训练速度设为0.1,允许误差设为0.0001,最大迭代次数设为3000次.通过调节隐含层的节点数反复地验证以优化网络结构,得到最佳的BP网络结构为9-6-5三层BP神经网络模型。用模型对预测集的25个未知样进行预测,结果表明两类模型对所有样本预测的正确率均达100%(表1)。为获得最佳建模方法,分析了两种方法对25个未知样的预测结果。两类模型对预测集的拟合结果与标准值之间的回归关系见图5。由图可知,两回归方程的斜率都接近于1,但特征波段模型预测集决定系数(R 2= 0.9994)比全波段模型(R 2= 0.9988)稍高,而预测标准误差(SEP= 0.0390)与预测误差均方根(RMSEP= 0.0383)则比全波段模型(SEP=0.0519;RMSEP= 0.0550)稍低,说明特征波段模型具有更好的预测效果,是一种优选方法。

图5 全波段模型(a)与特征波段模型(b)对未知样本预测值与标准值之间的关系
3 结 论
对5种稻米的分析结果表明,采用可见/近红外光谱技术进行稻米品种与真伪的鉴别是可行的,从而为稻米品种与真伪的快速、无损鉴别提供了一种新方法。比较分析结果表明,利用特征波段所建立的模型比全波段模型具有更高的预测精度,说明特征波段提取是进行模型优化的有效手段。